












猫鱼周刊 vol. 055 城市旅游就是打卡吗?

关于本刊
这是猫鱼周刊的第 56 期,本系列每周日更新,主要内容为每周收集内容的分享,同时发布在
博客:阿猫的博客-猫鱼周刊
RSS:猫鱼周刊
邮件订阅:猫鱼周刊
微信公众号:猫兄的和谐号列车
{kind=link}

摄于湖南长沙东风路文创园。这里原本是长沙北站原址,被改造成了一个非常小的文创园区。过年期间没有什么商家营业,游客也不多,蛮适合扫街的地方。
今天是农历正月十二了,给大家拜个晚年,各位身体健康万事胜意。
文章
可视化世界上所有的书
又是一个我非常喜欢的可交互式的文章。它把世界上所有的书按照 ISBN 放在一整个大书架上,还能实现无级放大。
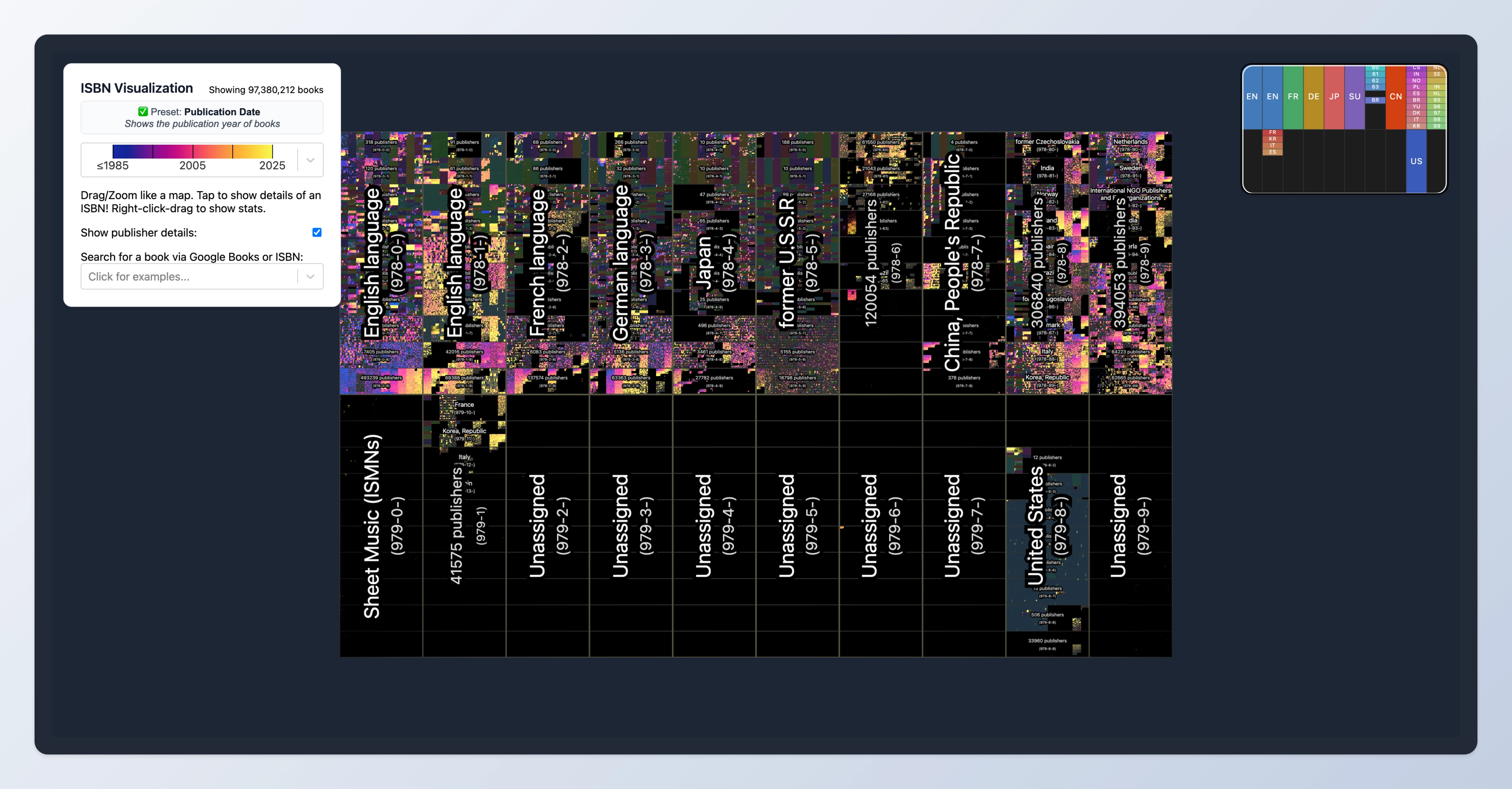
最夸张的是,当你慢慢放大的时候,每本书的书脊都会渲染出来。
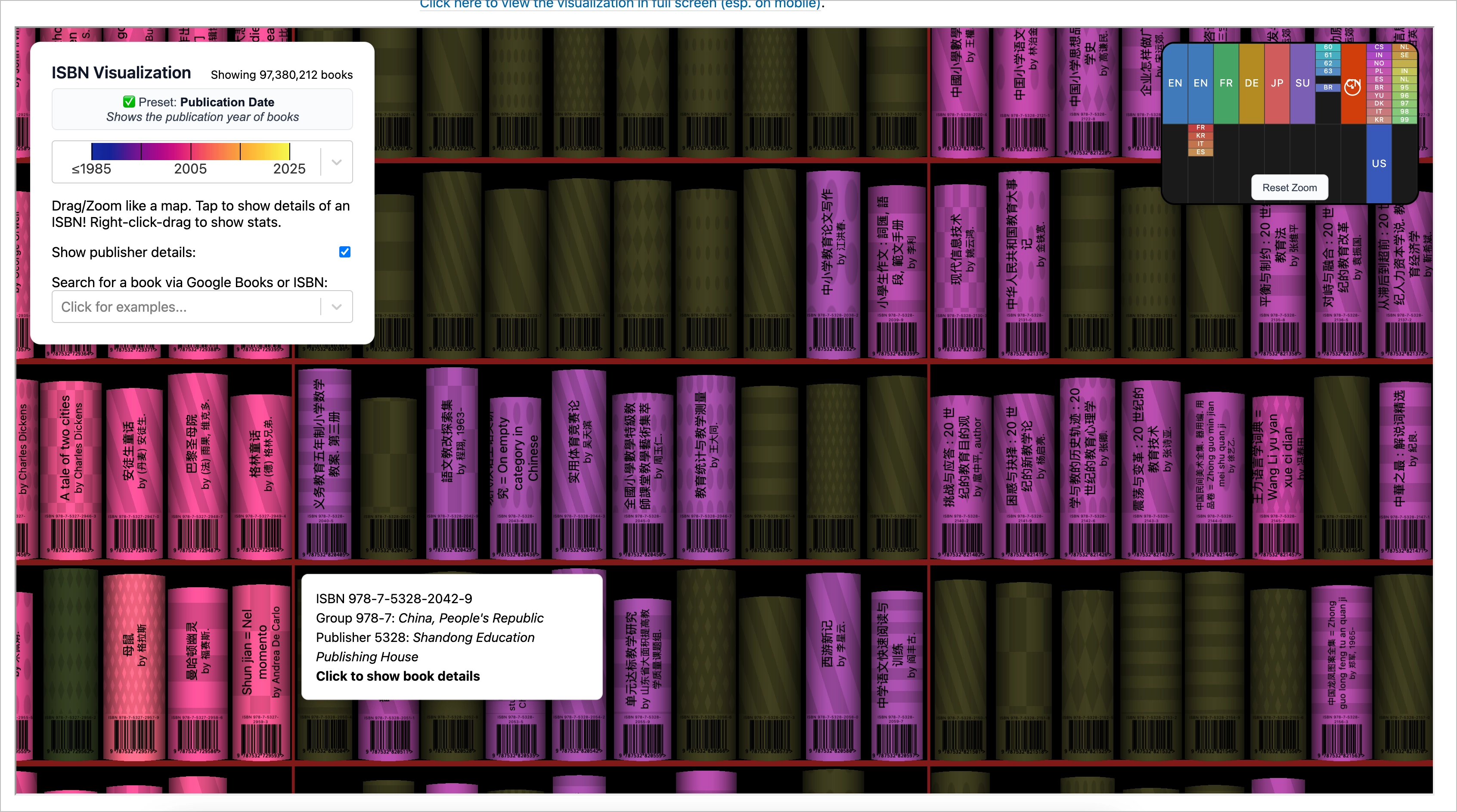
默认会按发表时间染色,另外还有按照图书馆存书量染色稀有度等。
文章里介绍了详细的实现方式,感兴趣可以看看。看到这个我想起做开源项目的时候经常忍不住去想的问题:做这个有什么用?我觉得答案是:没用,就是好玩。
图灵机
也是一个可交互式的文章,介绍了图灵机的原理。
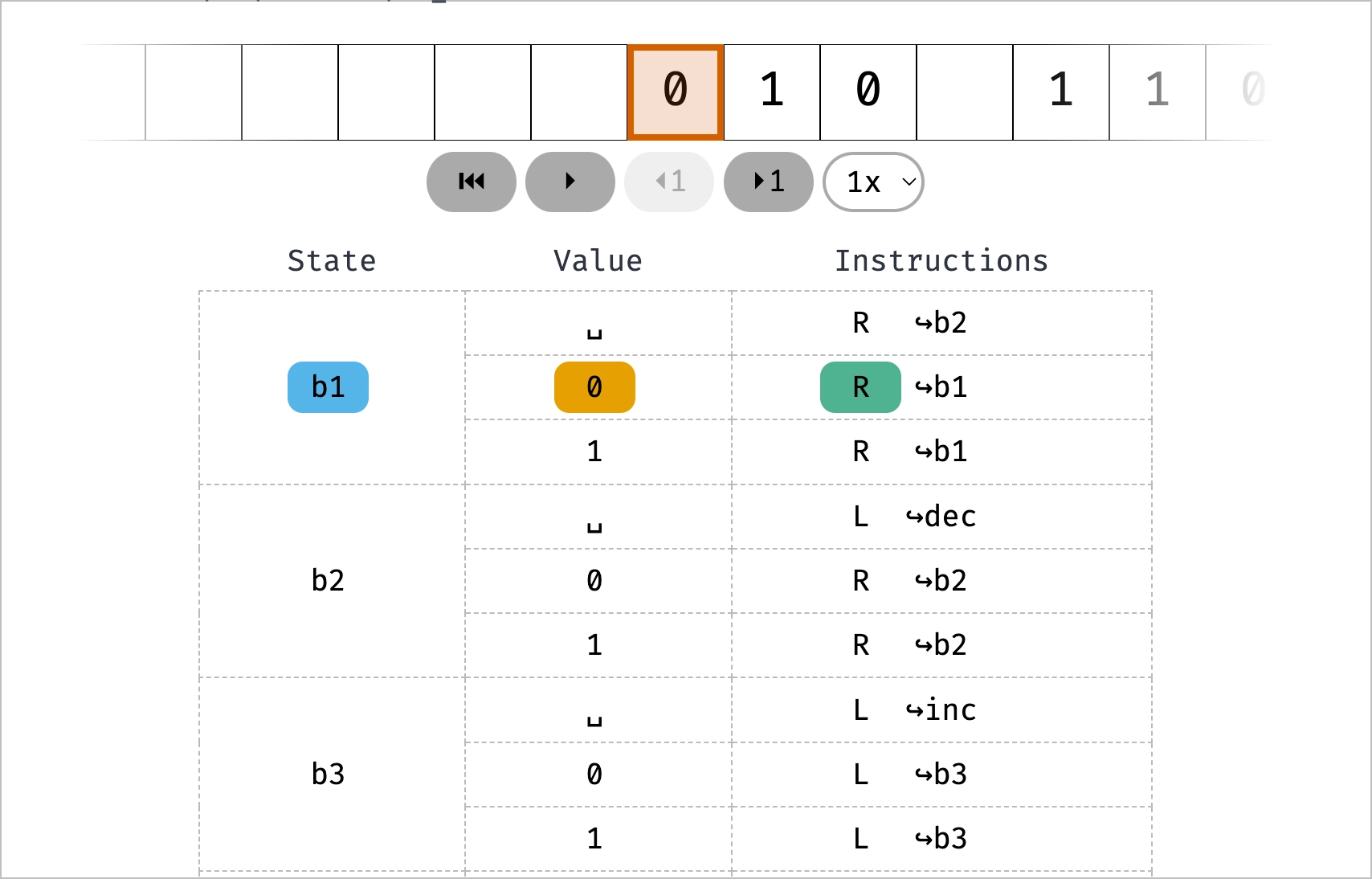
图灵提出了一种假象的机器,由一条无限长的纸带、一个读写头、一套控制规则有限的表和一个状态寄存器组成,机器只需要能执行五种指令:打印、向左或向右移动读写头、跳转至指定的状态以及停机,就能完成所有的计算。文章同时也解释了为什么计算机使用二进制会更加合理——在一个位上存储 0 和 1 比 0-9 更加方便。
如何让 LLM 闭嘴
greptile 是一家专门做 LLM Code Review 方向产品的公司,调研发现只有 19%的 good case,有 79%是 nit(可改可不改,多数人会忽略)。这个发现其实跟之前我探索的时候差不多,会产生非常多这类实际开发的时候不会被理会的问题。在解决过程中,他们发现:
- 反馈很重要,可以用来评估以及后续优化 comment 的质量。
- Prompt Engineering 没有用,few-shot 也没有用,甚至会使效果更差。
- 加一层 LLM 判断原来的 comment 质量,也没有用,而且会让耗时变长。
- nits 是主观的,每个团队的认知不一样。
- fine-tuning 没有尝试,成本、速度和可移植性都不佳。
最终他们使用的方案是:
- 按团队维度,记录生成的 comment 是否被 upvote/downvote,向量化后存储。
- 如果生成的 comment 与三个被 downvote 的 comment 相似度超过一定阈值,则会被屏蔽;如果与三个被 upvote 的 comment 相似度超过一定阈值,则通过;默认会通过。
采用该方案后,“满意度”从 19% 提升到 55+%。
在 vol. 051 中我提到过:
- 绝大部分 AI 不是一个产品,只是一个功能。
- 产品背后使用的模型不重要。
- AI 最好以无感接入的形式悄然融入现有的办公流程。
这个公司的产品就非常符合这些思想。他们的技术方案跟模型本身是无关的(没有微调模型),因此当能力更强、成本更低的模型出现时,切换过去即可。他们也没有打破常规的 CR 流程,也通过反馈的方式使得结果更能让一线程序员接受。
项目
MartialBE/one-hub

one-api 的二开。我原本以为这类产品最大的意义是减少不同厂商模型之间的差异,降低开发成本,结果却是各类卖课用来赚信息差的工具。
ZJU-LLMs/Foundations-of-LLMs

浙江大学团队的出品,分成传统语言模型、大语言模型架构演化、Prompt 工程、参数高效微调、模型编辑、检索增强生成六章。比较有意思的是,这个项目每周会更新一批新论文。我觉得应该是本科高年级/研究生在撰写,还蛮有意思。
快速看了前两章,大致就是我本科阶段的接触到的内容,讲述过程其实不是很适合没有 NLP 基础的人,对数学基础不好的人也不是很友好(对,就是我,看得云里雾里)。我抱着补补课,不求甚解的态度去看的,算是粗浅做做「继续教育」。
工具/网站
Proud Versioning
一种根据光荣程度的版本号规范,算是对 semver 的一种简化。

绘制城市简笔画
一个快速生成城市街道简笔画的网站,试着画了一下广州和深圳。
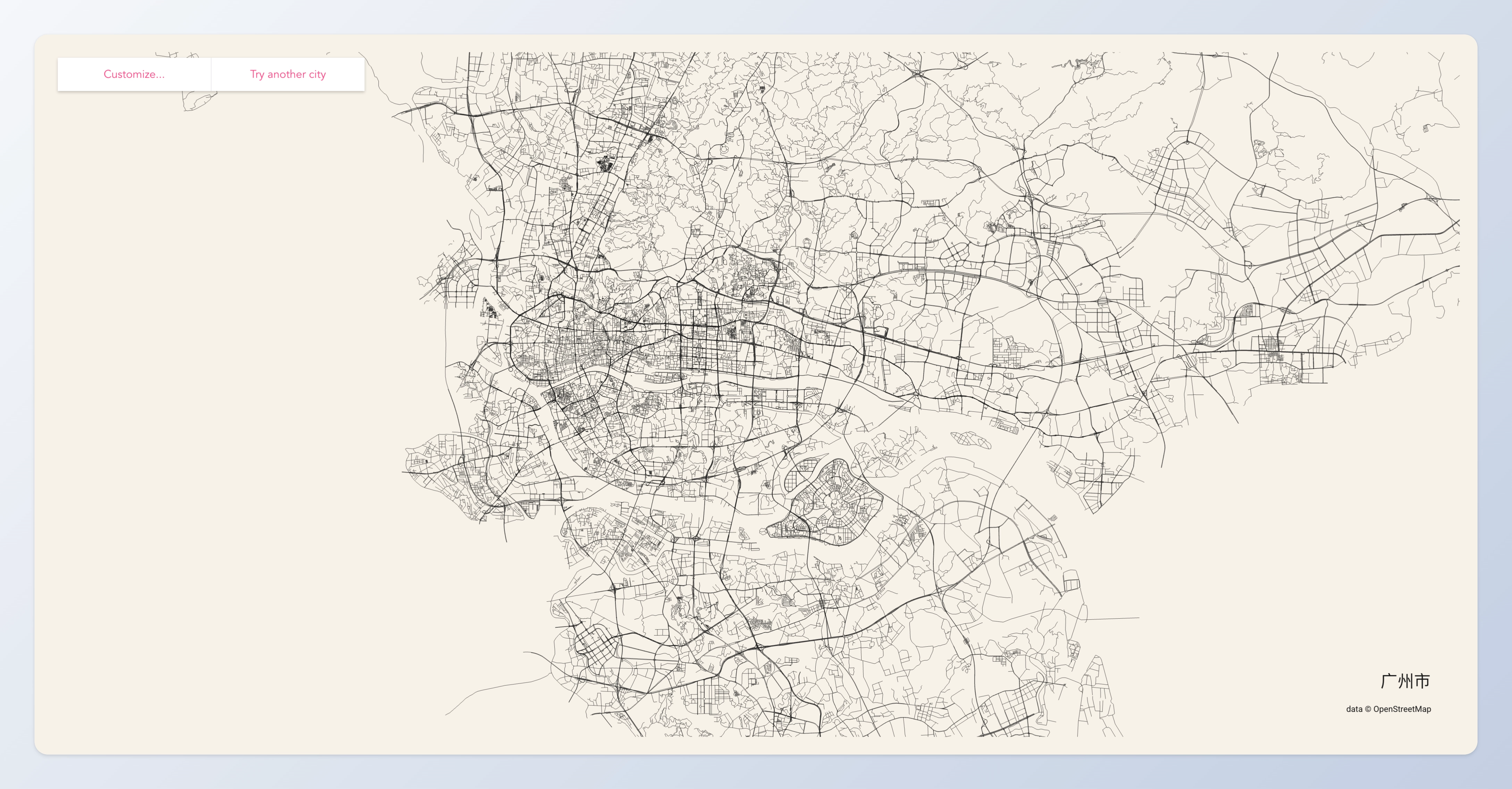
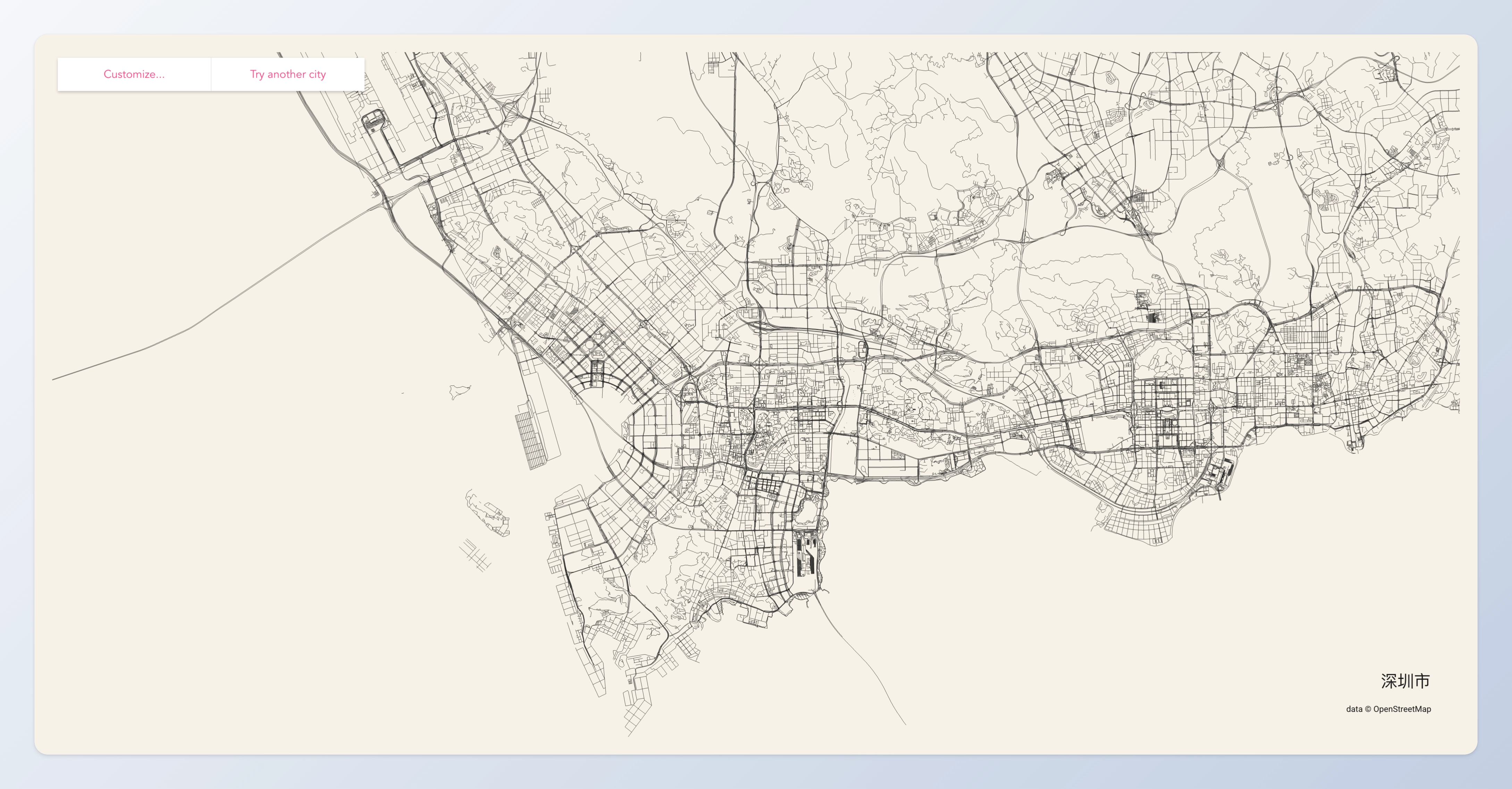
粗细的道路有点像城市的「脉络」,从简笔画其实也能看出什么地方是城市的核心,什么地方是郊区等等。另外,比较有意思的是,你可以试着在简笔画中找到一些你熟悉的地标、你家所在的位置等等。
/llms.txt
一种类似 sitemap.xml 的格式,使用自然语言帮助 LLM 更好地阅读网站。
不少网站已经有做这个,这里有两个网站收集了一些有 llms.txt 的网站:
想法
城市旅游就是打卡吗?
春节期间我去长沙玩了几天,去之前做了一些攻略,但发现这些攻略不是很对我的胃口。有很多所谓「打卡点」,例如 IFS 顶楼那个雕塑、旁边的步行街等等,这些东西每个城市都有,毫无特色。我很快就转变了思路,去找一些有城市味道的街区,去扫街,随缘找路边小店吃饭,不去排网红餐厅。
这算是不同的旅游风格。我去年在香港也进行了一次扫街,我直接就没有去通常推荐的旅游地方,而是沿着港岛线去走街串巷,摆脱了拥挤的游客,更加深度地去感受这座城市。对于拍照这件事,我不是很喜欢给自己拍照,对照片里有没有自己不是很有执念;另外,我觉得拍千篇一律的打卡机位其实没什么意思,你在网上能找到无数差不多一样的照片,不如自己去创作。
这次旅游也有一个非常有意思的地方,我带着从家里找出来的傻瓜胶卷相机,拜访了长沙一家胶片馆。老板非常善谈,店里也有非常多胶卷相机收藏。最后我把相机里 07 年拍摄的胶卷交给了老板冲洗,又买了一卷柯达全能 400 在后续的旅途中拍摄。这卷 07 年的胶卷最终洗出了差不多二十年前的影像,包括一位已经去世十年的长辈。也许后续我会再写篇文章讲讲我胶卷摄影的故事。
警惕 LLM 懂哥
想了好久,给这段这么个比较偏激的标题。我知道最近非常多博主创作 DeepSeek 相关的内容来蹭流量,效果也非常好;另外这个话题也非常出圈,在现实生活中也经常有人提起。目前我产生了一种生理反射,听到这个词就恶心。
我目前对它的理解是这样的:
- 一家中国企业,在硬件条件受限的情况下,训练并开源了媲美闭源商业模型的大模型。这是值得称道的,确实很优秀。
- 至于开源只开了权重这件事,其实大模型的「开源」就是这样,训练数据其实跟算法本身同样值钱,加上开放出来你再训练一遍意义不大,纯浪费电。
- 其实模型功能并没有很大的创新,推理也是 OpenAI 先做出来的,如果想体验完全没必要都去挤那个 R1。另外推理也不适合全部的应用场景,慢加上成本高,并非银弹。
回到标题「警惕懂哥」,是因为很多人蹭着这个流量开始卖课、卖 API,但其实他们屁都不懂。什么叫懂呢,至少把上面推荐那本书说的知识点脉络串讲清楚吧,我相信大多数在卖课的人压根说不出来(甚至连「语言模型」到底是什么都不知道)。
还有一个很火的话题是「本地部署」,这个也比较扯淡,先说观点:
- 所有在消费级硬件上能部署,能跑起来的,都是蒸馏模型,简单来说就是让小参数的模型「鹦鹉学舌」,并不能反映所谓「满血模型」的实力。换句话说,就是「看起来像」,也会比模型本身好,但是 benchmark 达不到「满血模型」的水平。
- 基于上一条,所有本地部署的都是玩具级别的,如果你手头正好有闲置的硬件,可以部署着玩,但是没必要因此去购入任何硬件。
- 如果是想用于生产,更加没必要自己搭建。规模上来的时候,吞吐量会是一个非常关键的指标,需要堆很多硬件才能保证。另外,集群的稳定运行也会耗费巨大的成本。使用公有设施在成本和性能上都更优。
摸着良心,我分享几个比较合理的方式:
- 个人体验玩,首先考虑官网的网页对话;如果要 API,可以用官方的,或者用硅基流动的。(硅基流动目前注册有免费的额度。)另外 OpenRouter 等现在也有,不过价格略高。
- 个人已有设备,可以尝试 Ollama 或 LM Studio自己部署一些蒸馏模型玩玩,这些产品已经把部署做到非常傻瓜式。
- B 端接入,可以考虑硅基流动里面带 「Pro」的模型,例如「Pro/deepseek-ai/DeepSeek-V3」,是独立的通道,只能充值使用,不能用赠送的余额。好处是不怎么会出现超时的问题,免费的那个目前基本不怎么可用。
- B 端有比较高的性能或稳定性要求,可以考虑各云服务厂商的预留实例。例如 AWS 可以用导入模型,或者硅基流动也有可以商务洽谈的预留实例。这类的吞吐量和成本也不如公共服务理想。
最后
本周刊已在 GitHub 开源,欢迎 star。同时,如果你有好的内容,也欢迎投稿。如果你觉得周刊的内容不错,可以分享给你的朋友,让更多人了解到好的内容,对我也是一种认可和鼓励。(或许你也可以请我喝杯咖啡)
另外,我建了一个交流群,欢迎入群讨论或反馈,可以通过文章头部的联系邮箱私信我获得入群方式。