












你不是在 vibe coding,而是在十倍速生成屎山
前言
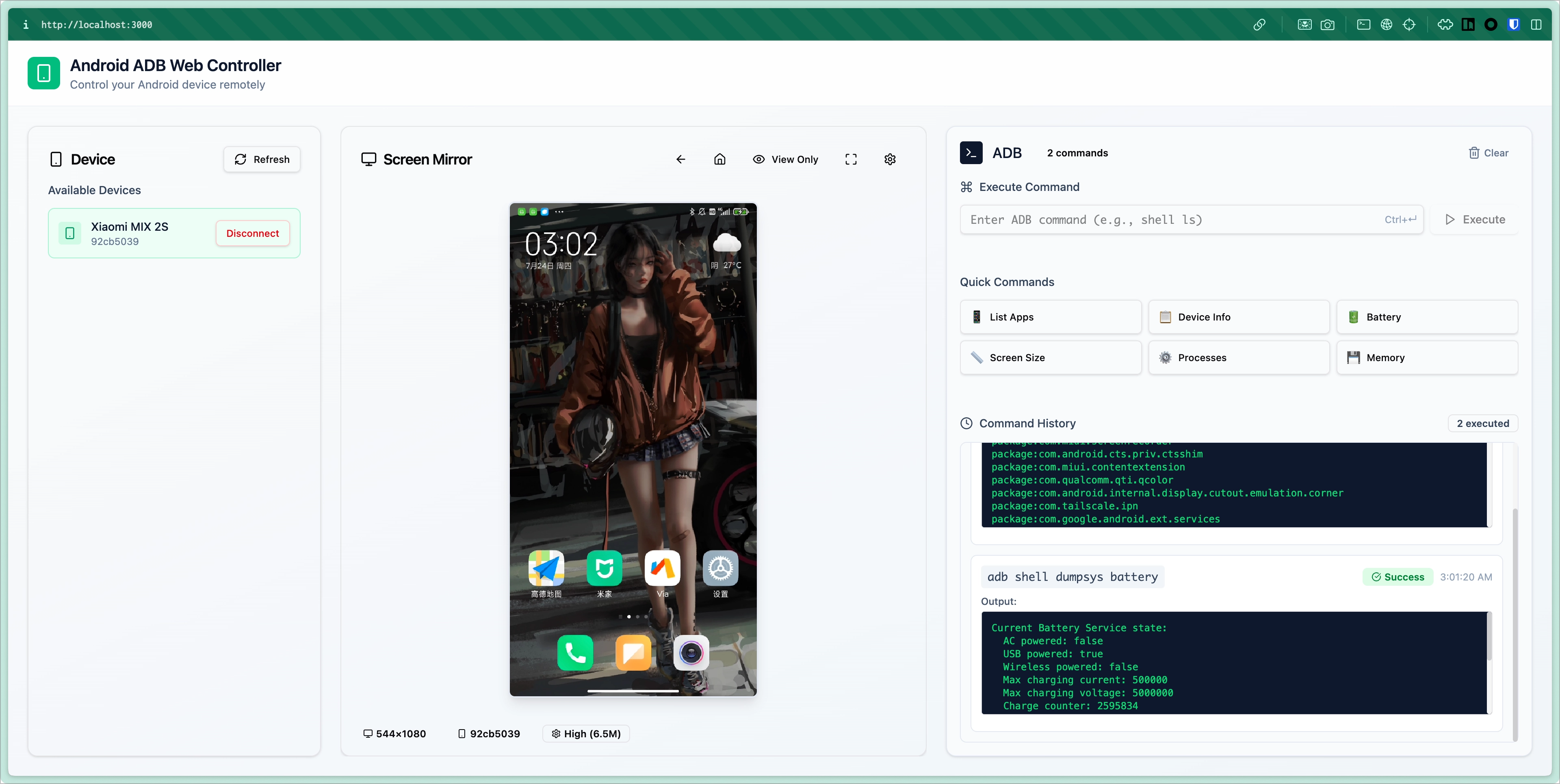
就在过去的一天我花了大概十个小时 vibe coding 了下面这么个玩意,主要有这些功能:
- 列出连接到服务器的设备列表
- 连接设备,通过 scrcpy 实时监看屏幕,并支持控制
- 支持执行 ADB 命令
事先声明,我是 AI 编程的积极拥护者,去年初我还写过一篇用 GitHub Copilot 写前端的文章。时隔一年多,这个领域涌现出了很多新产品,Agent、MCP、Cursor、Claude Code 等等的推出,我觉得是时候更新一下这方面的体验了。
先说一下这趟 vibe 旅程的花费和成果吧。我主要使用了 Cursor(主要是 claude-4-sonnet 和 Auto 模式),以及 Claude Code(Kimi K2 和 Claude 模型)。其中 Cursor Pro 的额度被我用完了,Claude Code 花费了十几刀。「产出」的代码有 10000 行左右,虽然中间有部分组件的代码,我估计实际逻辑代码大概也有几千行。
屎山
是的,标题里说得很清楚了,我基本上是在十倍速生成屎山。这本来应该是一篇经验介绍的文章,但是我觉得非常应该「把丑话说在前头」,而且这也是我在 vibe coding 中最大的心得。
我之前就说过:AI 决定下限,人决定上限。我觉得 vibe coding 分为以下几种情况:其一,你对要实现的功能非常熟悉,只是让 AI 代劳敲键盘的工作;其二,你对要实现的功能略知一二,要你自己拿起来写会磕磕绊绊;其三,也是我这次的情况,你对要实现的功能基本一无所知。第一种情况下,你跟 AI 很可能会配合得亲密无间,而后两种情况,你的体验估计够呛。后面的体验基本都是基于第三种情况来说。
一旦你开始 vibe coding,你就只能 vibe 到底了。
在你不懂的时候,AI 一旦写出一大段代码,这会迅速超出你的上下文范围。是的,虽然 AI 只有 200K 上下文,但这已经比大多数人能理解的上下文要大得多了(我认为一个普通的程序员上下文应该在 500 行代码左右)。这时候你的代码质量就会快速崩塌:混用 AI 模型、多次生成之间使你的代码库出现了多种不同风格的代码;不清楚最佳实践,导致有各种可能蹩脚的实现。很快你就会发现你陷入一种循环:贴错误日志/截图/描述错误 - AI 修改 - 无脑接受变更 - 运行,你对代码已经完全失去了掌控。
在 vibe coding 十个小时后,我的代码库里出现了几千行我根本看不懂也没法维护的代码,以及一个「好像能用」的产品。说实话,这个项目如果要我自己一边查文档一边写,估计至少要花上一周。但是这在工程上没有太大的意义,完全就是十倍速生成屎山。
工具简评
我这里决定把 Claude Code 和 Cursor 的 Agent Mode 放在一起说,他们在设计上是类似的,都是有个模型做规划(TODO),然后分步执行,调用工具这样的路子。先说优点:
- 自动选择上下文的功能太好了,相比以前需要手动选是个极大的改进(这点 Claude Code 做得更好,交互上基本只用描述需求;Cursor 可以手动选择来增加精确度,但是自动的也不错)。
- 规划的设计也很不错,如果发现方向不对可以尽早停止,在大型任务或者用户完全不懂的时候能取得更好的效果。
- Fetch/Doc 工具非常实用,能避免一些冷门的包产生大量幻觉。
- 能自动修复 lint,这点对强类型语言非常友好。
缺点也有不少:
- 鬼打墙,遇到卡点还是会反复加日志调试,基本上解决不了。我觉得第一蛋疼的事,AI 往代码里加了一大堆日志,而且还带了很多 emoji,怎么都删不完。
- 遇事不决删代码,mock 实现。这是我觉得第二蛋疼的地方。他会冠冕堂皇地说「我们尝试一个最简单的实现」,结果就是给你 mock 掉,甚至留个 TODO 在注释里,太过分了。
- 烧钱快,Claude Code 可以在半个小时内烧完十几刀;不过换成 Kimi K2 的话相对经济很多。
- Claude Code 没法贴图片,在遇到布局、样式问题时,只能通过语言描述。
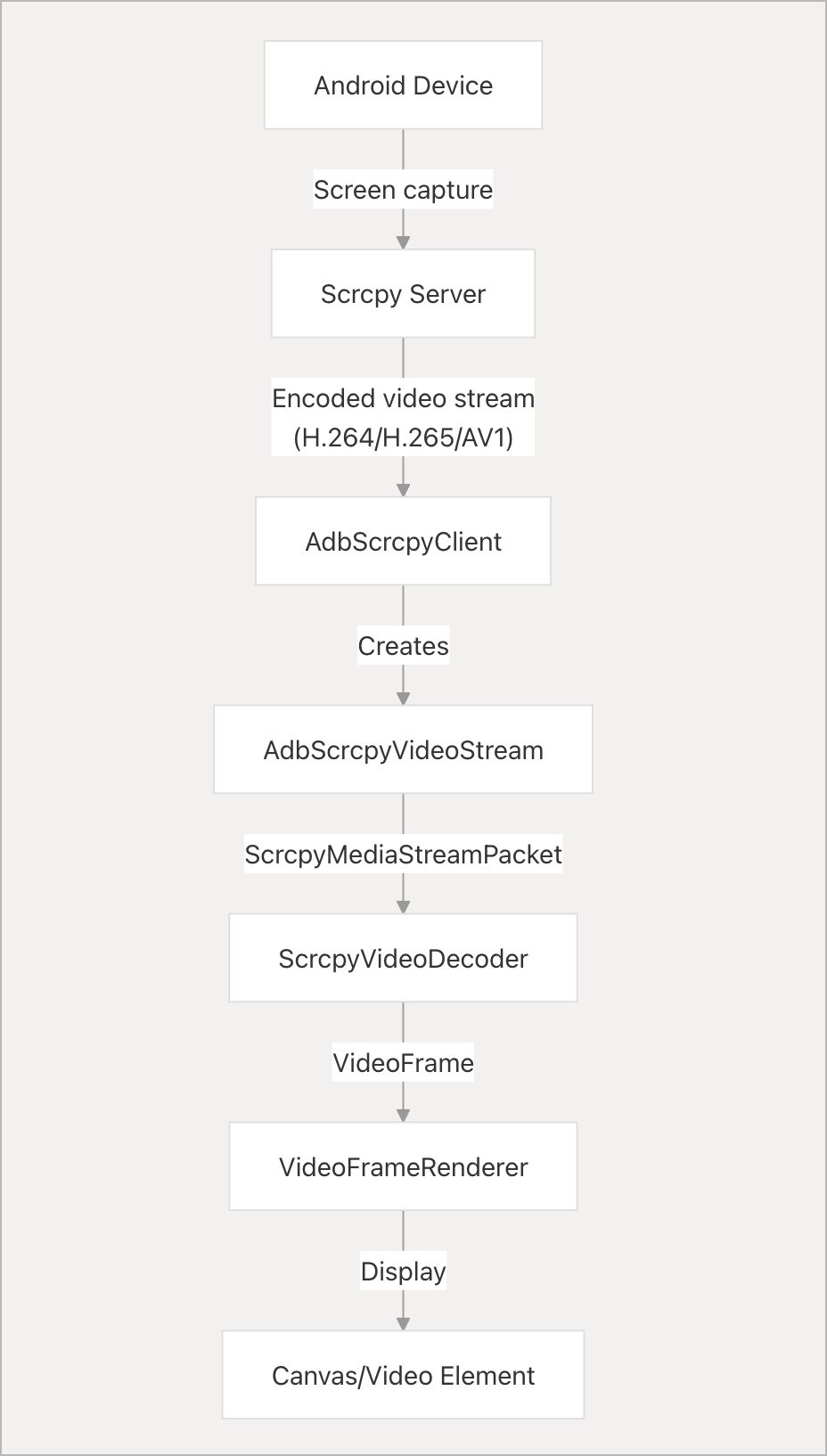
- 在架构、时序等问题上能力尤其弱。在写 scrcpy 的实现的时候,实际上 scrcpy 的服务端运行在安卓设备上,然后需要服务端实现一个 scrcpy 的客户端,然后起一个服务端,推流给客户端(浏览器)。一开始我没搞懂这个逻辑,而 AI 一直想在浏览器运行 scrcpy,纠结了非常久。
一些技巧
补充上下文
Cursor 和 Claude Code 都支持 MCP,有两个我觉得必备DeepWiki和context7。
DeepWiki 能让帮助 AI 快速梳理项目结构,理解包的使用,找到对应的 API 。它甚至提供了一个问答的功能,可以让 DeepWiki 的 AI 帮你找到项目中对应的实现。例如我这个主要是想参考 midscene 的 android playground,我就让他去读项目的 DeepWiki,理解 scrcpy 的实现。又例如,ya-webadb这个包中,DeepWiki 梳理出了这个实现的架构,这其实对我的理解也有很大的帮助。
至于 context7 则能够给 AI 提供对应版本对应包的 API 文档,极大地减少它出现幻觉乱编 API 的情况。
当然了,你可以直接贴网页地址,或者也可以通过 Cursor 的 @Docs 文档去指定对应的开发文档,来手动地给 AI 增加上下文。
另外,虽然 Agent 模式会自动选择上下文,你可以手动指定一些上下文来帮助它更好理解和解决问题。在 Cursor 中,你可以在代码、终端中按 Cmd + I 来添加多个上下文,或者按 @ 展开下拉框选择。
按照需求选择模型
主观来说 claude-4-sonnet >= gemini-2.5-pro > Auto > Kimi K2,我推测 Auto 应该是 DeepSeek-R1 或 GPT-4.1 之类。分享几个零散的观察:
- claude-4-sonnet 和 gemini-2.5-pro 在 Cursor 上都能触发类似 Claude Code 的 、TODO 模式,Auto 则不能。
- 接上条,如果你要做比较复杂的修改,建议还是用 claude-4-sonnet 和 gemini-2.5-pro 这两个。但是他俩特别慢,如果修改比较简单(例如只是简单改改布局,可以用 Auto)。另外,Auto 没有用量限制,在超出额度之后就只能用这个。
- Gemini 不喜欢说中文,Kimi K2 会被上下文带偏开始说英文,如果对这个有要求建议还是用 claude-4-sonnet;Auto 则基本会说中文(所以我觉得他是 DeepSeek)。
- Kimi K2 是显著便宜,能力也是显著地差,几乎完全没法独立解决问题。
能力强的模型一定贵而且慢,因此不可能成为万金油。Cursor 中的 Auto 可以算是一种万金油,在解决复杂问题时有一定的竞争力,解决简单问题时速度则很快,废话也少。
回到一开始说的三种情况,第一种情况我建议你用 Auto,或者 Kimi K2,或者 DeepSeek 也行,甚至最基础的 Tab 自动补全都已经很好用,因为只是帮你省打字功夫。后面两种情况,如果你要 vibe 到底,那基本只能选 claude-4-sonnet 或者 gemini-2.5-pro ,除了他们没人能看懂你的屎山。
约定好规范
Cursor 支持 cursor rules,也就是一个 markdown 文档,来告诉 AI 如何解决问题,或者代码的风格等。我没有一个完整的规则可以分享,但是网上有很多,可以自行参考。我提供一些思路:
- 规定框架、偏好的包,避免引入多个类似的库。
- 适当解释你的项目结构,例如服务端的结构,希望 model 层和 service 等分离等。
- 代码规范,大小驼峰这一类,避免风格不一致导致强迫症难受。
- 语言风格,我不喜欢让 AI 再总结自己的变更,因为基本上我需要 review 代码。
写 AI 友好的代码
这点我放到了最后,也是我觉得最难的。在规范良好、逻辑清晰的代码上,AI 的表现最好;而在一些老项目、屎山上,AI 很难做出有效的修改。其实所谓 AI 友好,其实也是对人友好,也就是「可读性」。把函数拆得原子化、加单测、加注释、简化逻辑,这些都是老生常谈的问题了。
最后
激动的心,颤抖的手,写到现在已是凌晨四点半。在分享技巧之余我想回答的一个问题是,「AI 编程是否能提升效率」。我觉得能,但是有限,而且很大程度上还是取决于使用者本身。一是 AI 并没有显著降低人的认知负担,你还是要理解、维护同样代码量的东西;二是在屎山堆积的业务代码里,很难找到 AI 大显身手的空间;三是使用者的认知水平、技巧决定了 AI 的能力上限。
当然,市面上还有很多工具,例如 Gemini CLI、Kiro 等,我还没来得及去体验;本次的过程也是从「新手」的角度去体验,我也知道有些工作流、MCP 之类的组合的高阶玩法,我也没有涉及,但我认为总体的体验应该并无大异。我并非想泼 AI 的冷水,而是要跟它磨合好,人和 AI 协作必然是主流,人自身的能力和认知会更加重要。