爬取JD商品评论并数据可视化
本文参考了知乎文章 https://zhuanlan.zhihu.com/p/60444767
思路
阅读文章后发现原来还可以通过抓取json的方式爬评论,不需要再去一个个数据去找页面标签等等复杂的操作,直接请求然后解析返回的json数据(超级整齐)。
requirements
requests
pyecharts
pandas
jieba
wordcloud
matplotlib
爬取评论
先贴代码
# -*- coding:utf-8 -*-
import requests
url = '<https://sclub.jd.com/comment/productPageComments.action?productId=100004325476&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1>'
# 请求头
headers = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'Referer': '<https://item.jd.com/100004325476.html>',
'Host': 'sclub.jd.com'
}
def get_comment(url):
# 请求
req = requests.get(url, headers=headers)
# 数据处理
res = req.json() # 转换成python对象
comments = res['comments']
total = []
for comment in comments:
data = {
'id': comment['id'],
'content': comment['content'],
'score': comment['score'],
'userLevelName': comment['userLevelName'],
'userClientShow': comment['userClientShow'],
'mobileVersion': comment['mobileVersion']
}
total.append(data)
return total
if __name__ == '__main__':
res = get_comment(url)
print(res)
这里需要特别注意的是请求头的处理。如果用一般的请求头,如'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36' 会发现返回一些奇怪的数据。打开开发者工具,具体看里面的请求头(不详细讲,可以百度),然后copy到代码里。
爬取并存储
还是先贴代码
# -*- coding:utf-8 -*-
import get_page_comment as cm
import store_comment as st
import time
import random
# 构造url
urls = []
for score in range(1, 4, 1):
for page in range(0, 10, 1):
ori = "<https://sclub.jd.com/comment/productPageComments.action?productId=100004325476&score=%(score)d&sortType=5&page=%(page)d&pageSize=10&isShadowSku=0&fold=1>" % {
'score': score, 'page': page}
urls.append(ori)
# print(urls)
# 获取评论
res = []
for url in urls:
s = cm.get_comment(url)
res += s
print(s)
time.sleep(random.uniform(1, 3))
# print(res)
# 存储
st.store_data(res)
这里url的构造需要用到两个变量,灵机一动想到用格式化字符串的方式来构造,代码更加pythonic了! 还有需要注意的就是要加入随机的sleep防止被反爬。 复习一下如果使用selenium是不需要做反爬的超级方便的呢!
jieba分词和词云
然后就是用jieba分词做词云了 贴下代码
# -*- coding:utf-8 -*-
import pandas as pd
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 从xls读入数据
data = pd.read_excel('JD.xls')
comments = data['content']
text = ''
for comment in comments:
text += ' '.join(jieba.cut(comment))
wordcloud = WordCloud(
font_path="C:/Windows/Fonts/msyh.ttc",
background_color="white",
width=1000,
height=880,
stopwords={'耳机', '京东', '非常'}
).generate(text)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
具体的用法在我的另一篇博客里有详细讲 https://blog.csdn.net/weixin_43409309/article/details/88649728
得到的词云:

pyecharts得到图表 同样先贴一下代码
# -*- coding:utf-8 -*-
import pandas as pd
from pyecharts.charts import Bar
# 从xls读入数据
data = pd.read_excel('JD.xls')
userLevelName = data['userLevelName']
count = userLevelName.value_counts() # 对各项计数
num = count.tolist() # 转换成python对象
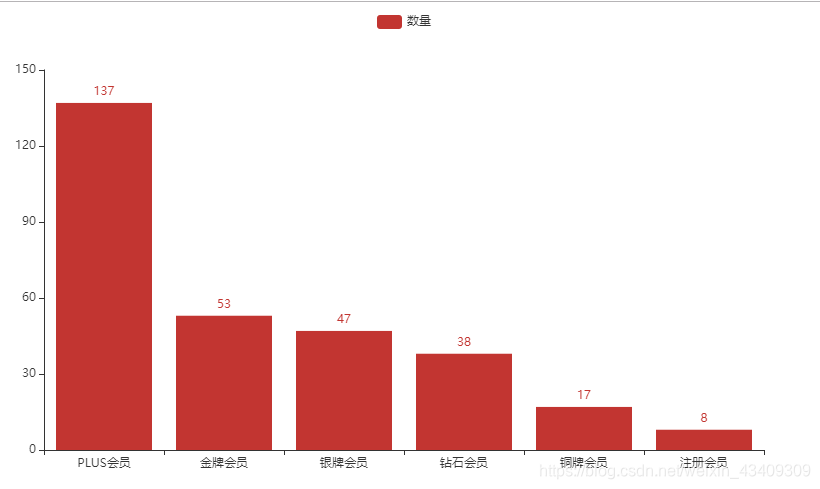
bar = (Bar()
.add_xaxis(['PLUS会员', '金牌会员', '银牌会员', '钻石会员', '铜牌会员', '注册会员'])
.add_yaxis('数量',yaxis_data=num))
bar.render('a.html')
过程很简单,用pandas读入数据,然后用pandas对某一字段进行统计,转换成list,然后用柱状图表示。
得到的结果:
总结
整个过程总的来说不是太难(因为有之前知识的铺垫),主要是直接抓取返回的json这一个比较有意思。json的数据十分整齐,既容易获得又容易处理,尤其对于这种动态的网站,不失为一个好思路。
License:
CC BY 4.0