












猫鱼周刊 vol. 058 DeepSeek 的开源是一种大义

关于本刊
这是猫鱼周刊的第 59 期,本系列每周日更新,主要内容为每周收集内容的分享,同时发布在
博客:阿猫的博客-猫鱼周刊
RSS:猫鱼周刊
邮件订阅:猫鱼周刊
微信公众号:猫兄的和谐号列车
{kind=link}

尖岗山上的落日,城市高楼、主干道、夕阳和远处的大桥同框。周刊写到一半去爬的山,半个小时到山顶,欣赏了一场落日。
本期尝试把「想法」栏目移到「文章」后面,虽然有「想法」这个栏目,但其实「文章」这部分已经有非常多我的想法在输出。其实这两个栏目的差别是,一个是有来源的,会希望读者先看看原文,再来看我的思考(又或者直接吸收我蒸馏的想法,x);另一个是比较没有由头,可能是我平时一拍脑袋的想法或者跟朋友聊起的想法。
文章
一些模型发布
这两周有比较多模型的发布,主要是 Grok 3、Claude 3.7 Sonnet、GPT-4.5,就合起来一起说,同时附上官方的发布原文。
- Grok 3:支持推理(Think),从 benchmark 上看比 DeepSeek-R1 和 o1 等都强;DeepSearch 功能,推理+工具使用,对标 deep research。API 暂时还没开放。
- Claude 3.7 Sonnet:也是支持推理的小改款。benchmark 结果感觉比 DeepSeek-R1 略强,不过在 Cursor 里用起来感觉没明显差别。
- GPT-4.5:GPT-4 的升级,有更加泛化的知识,而且减少了输出中的废话。另外,它比 GPT-4o 更慢而且更贵,不是 4o 的替代。
一些想法:
- 上期就提到,从基座模型到推理模型不难,因此其实可以看到最近各家都在往这个做。推理模型的能力其实最依赖的还是基座模型的性能。
- deep research(推理+工具使用)的模式,对模型性能的提升非常明显。在之前提到的 Humanity's Last Exam测试中,OpenAI 的 deep research 取得了 26.6% 的准确率,而基座模型基本上只有不超过 10%的准确率。(via OpenAI)
- GPT-4o 可能是个蒸馏模型,OpenAI 明显是有更加大参数、能力更强的模型(GPT-4/4.5),但出了个更加快而且便宜的 4o,除非有什么其他闻所未闻的黑科技,蒸馏看起来是个比较合理的解释。一些讨论
社交关系中的“主动降频”
作者和高中同学聚会时的感想。
我不知道从什么时候养成了一个习惯,在跟别人交流的时候,尤其是陌生人,我会下意识的思考对方说话所包含的潜在逻辑和原因,我还会去思考对方这么说的原因的一些可能性。
说回这次跟朋友的聚会,文章标题说的主动降频其实就是主动取消这种下意识行为,用十年前的自己和大家相处。
有引起共鸣,我平常在人际关系中也比较敏感,这种敏感会导致非常多苦恼和纠结。另一个话题其实是信任,更加信任你的朋友、同事甚至陌生人,相信对方没有恶意,心智负担会低很多。
注释是你的好朋友
作者收集了一些关于注释的文章,也谈到了他对注释的理解。里面的文章列表非常值得一读。
国内编程教育(至少我接受到的教育)非常忽略注释的重要性,只是说「这部分不会执行」一笔带过,在工作中也鲜有见到有人非常认真去写注释。对了,我见得最多的注释就是一大坨「不会被执行」的过时代码。
我觉得写注释最简单的原则就是,如果某个地方你写的时候非常困惑,或者需要查阅某个文档,那么把你的想法/看的文档用注释记录下来,一定不会错。将来自己或者其他人再遇到这块代码,就不需要重头踩一遍原来的坑。
另外一个概念是,注释也是代码的一部分,也是需要维护的。当注释的内容过时时,一定要去更新,不然就会出现注释撒谎的情况。
这两点其实已经非常容易做到了,但我在工作中很少见到有这样的实践。而在好的开源项目中,一个函数甚至都会有几乎有跟代码同等行数的注释在做说明。
想法
LLM 工具化、实用性的一些思考
自从 LLM 问世,或者说火爆,在日常使用中用得最多的还是聊天和代码生成这两个场景。中间有过不少昙花一现的想法,也做过一些开源项目,最终都没有持续用下来。
总是蠢蠢欲动用 AI 想给自己做一些实用的工具,但是到头来可能发现编排完或者开发完,根本不会多用上。目前用的最多的一个编排就是周刊摘要的提取,而它一开始是 Quail 上的一个功能,只是为了方便我的编辑流程,我自己又再做了一个而已。
AI 的出现不会创造需求,需求还是原本的需求,AI 只是一种万金油实现而已。
对互联网产品经理来说,大可不必从 AI 出发去想需求,发掘需求还是和以前一样的,不一样的只是技术上可以用 AI 去实现了而已。
DeepSeek 的开源,是一种大义
最近可以看到非常多云服务厂商等针对私有化部署在 2B、2G 疯狂收割,会感叹 DeepSeek 把模型权重开源真是让别人捡大漏赚得盆满钵满。
但其实单靠 DeepSeek 自己根本没有那么多算力去供应这个需求,把模型权重开源,让别的有算力的厂商去廉价普及才是更可行的路。一方面 DeepSeek 算是赚足了流量,一时间街头巷尾猫猫狗狗都在谈论 DeepSeek,名声算是打出来了;另一方面它真正做到了小米的 Slogan「让每个人都能享受科技的乐趣」,这在国内比 OpenAI(国内不能合法用)、Copilot(仅限软件开发领域)能触达的人群更广。
项目
moepush

又一个消息推送服务,基于 Cloudflare 部署,应该也是「零成本」的。
我在做 Heimdallr 的时候也考虑过这个方向,里面有两个点我觉得比较难受:vendor-lockin(供应商绑定)以及依赖数据库。首先是 vendor-lockin,使用大量供应商特性/特有的服务进行构建,非常限制部署的灵活性,还有个风险是,哪天这个服务商开始收费,当前的架构就需要大改。另一个是数据库的依赖,考虑免费、稳定这些因素的时候,架构自然是越简单越好。
当然多一个数据库可以做的事情就多很多,例如消息聚合、定时发送、多租客等等 feature 都可以做了,做渠道管理也方便很多。我在考虑给 Heimdallr 也做一版有数据库的,这个项目也许会成为我的学习对象。
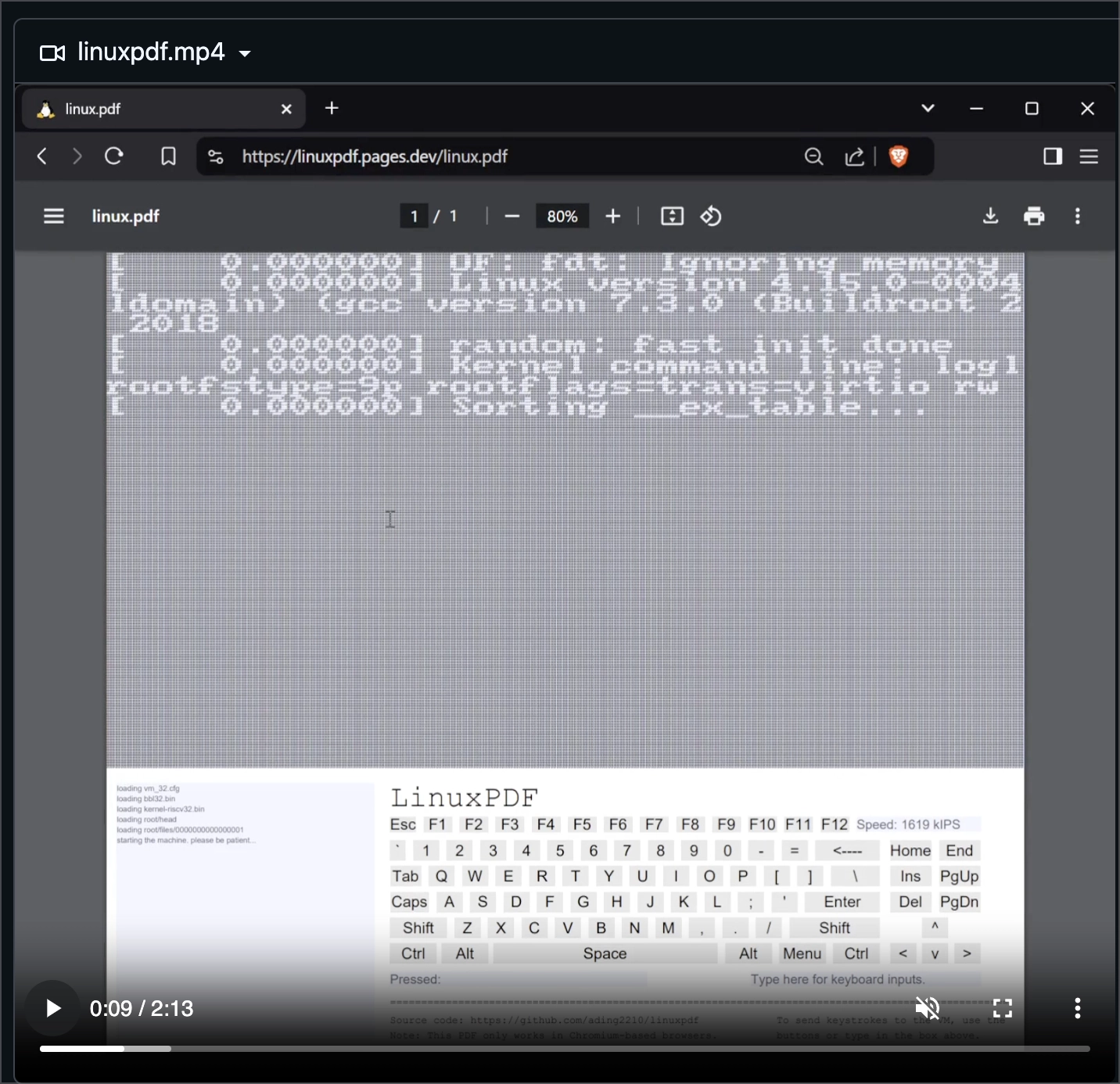
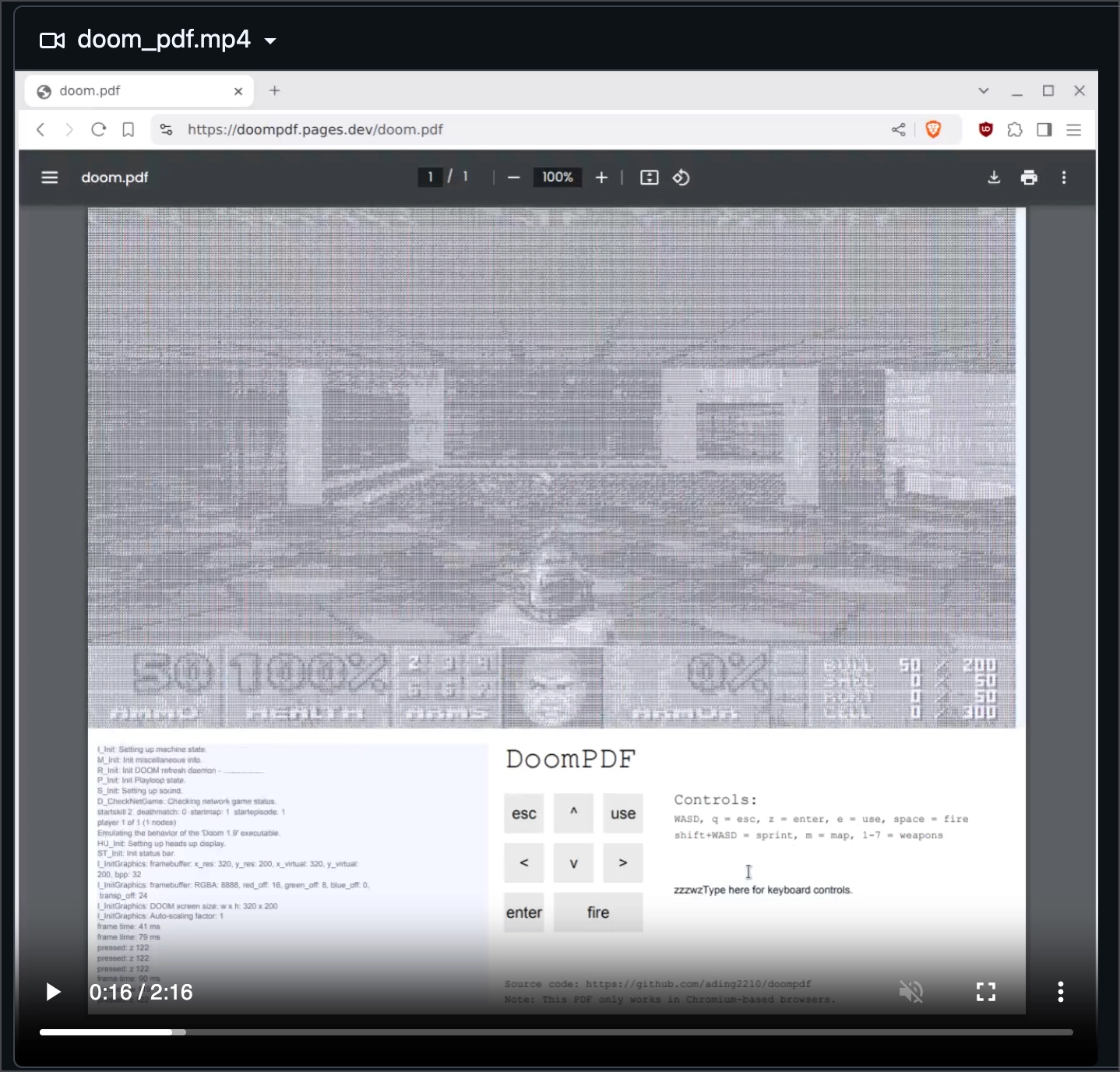
linuxpdf

文档不只能运行恶意代码,甚至能运行一整个完整的 Linux,更甚至能运行 doom。
Xiaomi-BootLoader-Questionnaire

小米解锁 BL 的题库。曾经「为发烧而生」的小米,哎。
看了下题目的内容,除了有些精神上的送分题,剩下的题目专业性颇强,甚至考察了一些安卓开发的内容。很难说这些题目是在拦谁,纯粹爱折腾的高中生、热爱玩机的非开发爱好者就被这样拒之门外。
不允许解 BL 我认为就是厂商不愿意为用户折腾产生的问题买单。且不谈设备所有权、使用权这些 BS,小米我觉得还是对科技有热爱的,连这小部分用户群体都考虑不到,有点「下头」。
ZeroOmega

SwithcyOmega 的 fork,兼容了 manifest v3。目前来说 SwithcyOmega 还没遇到什么问题,存档备用。
最后
本周刊已在 GitHub 开源,欢迎 star。同时,如果你有好的内容,也欢迎投稿。如果你觉得周刊的内容不错,可以分享给你的朋友,让更多人了解到好的内容,对我也是一种认可和鼓励。(或许你也可以请我喝杯咖啡)
另外,我建了一个交流群,欢迎入群讨论或反馈,可以通过文章头部的联系邮箱私信我获得入群方式。